Please make sure to check out the setup article titled ‘World of Data Science’ before moving onto this.
When dealing with data, there are various ways to go about handling it. Today, we’ll look at using the mean of the set/column data to fill up unknown/missing data.
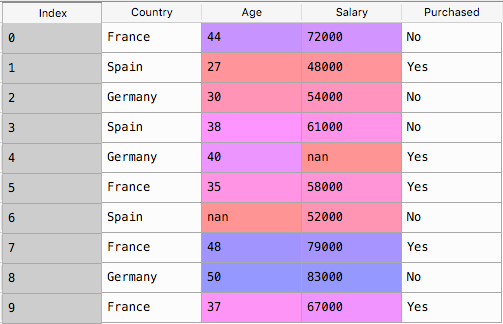
From the data in the table, we can see that we are missing 2 values from it. One with respect to Germany’s Salary and the other with Spain’s age. We’ll fill these values up with the mean value of the columns.
Spain’s age would be equal to the mean of the entire Age column and Germany’s salary would be equal the mean of the entire Salary column.
Let’s first look at achieving this python:
First up, load the dataset from the csv used in the article stated above.
independentVars = dataset.iloc[:,:-1].values
dependentVar = dataset.iloc[:,3].values
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = 'NaN', strategy = "mean", axis = 0)
imputer = imputer.fit(independentVars[:, 1:3])
independentVars[:, 1:3] = imputer.transform(independentVars[:, 1:3])
Spyder 3.2.8 doesn't support viewing object arrays in the variable explorer. In order to view the calculated mean values, we’ll need to print(independentVars) in the IPythonConsole section at the bottom right window. You will find the resultant set as below.
print(independentVars)
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 63777.77777777778]
['France' 35.0 58000.0]
['Spain' 38.77777777777778 52000.0]
['France' 48.0 79000.0]
['Germany' 50.0 83000.0]
['France' 37.0 67000.0]]
If you’re comfortable using R over python, we could do the same in the following manner:
dataset$Age = ifelse(is.na(dataset$Age),
mean(dataset$Age, na.rm = TRUE),
dataset$Age)
dataset$Salary = ifelse(is.na(dataset$Salary),
mean(dataset$Salary, na.rm = TRUE),
dataset$Salary)
From the above code, we can see that, we are first trying to identify cells that have NA/missing values, so when a cell with missing value is found, we simply replace it with the mean of the entire column in place, else retain the actual salary. If you set na.rm to FALSE, you’ll not see the mean resultant change in the actual dataset for the missing value cell.